GENE_CLUSTER
Cluster Genetic Expression Data
GENE_CLUSTER
is a FORTRAN90 program which
divides a set of genetic data into clusters.
The data comes from genetic expression experiments.
Each cluster will be defined in terms of a representative data
vector, and the clustering minimizes the sum of
the squares of the "distances" of each data point to its cluster
representative. Here, the "distance" may be either the Euclidean
distance or a similarity measure based on angles.
The data to be examined is assumed to be stored in a file.
The file is assumed to contain a number of records, with each
record stored on its own line.
Each record, in turn, contains a fixed number of data values
that describe a particular gene expression experiment.
Each record will be regarded as a point in N dimensional space.
The program will try to cluster the data, that is, to organize
the data by defining a number of cluster centers, which are
also points in N dimensional space, and assigning each record
to the cluster associated with a particular center.
The method of assigning data aims to minimize the cluster energy,
which is taken to be the sum of the squares of the distances of
each data point from its cluster center.
In some contexts, it makes sense to use the usual Euclidean sort
of distance. In others, it may make more sense to replace each
data record by a normalized version, and to assign distance
by computing angles between the unit vectors.
Licensing:
The computer code and data files described and made available on this web page
are distributed under
the GNU LGPL license.
Languages:
GENE_CLUSTER is available in
a FORTRAN90 version.
Related Data and Programs:
ASA136,
a FORTRAN90 library which
is an implementation of the K-Means algorithm.
CITIES,
a FORTRAN90 library which
defines various problems associated with a set of
"cities" on a map.
KMEANS,
a FORTRAN90 library which
contains several implementations of
the K-Means algorithm.
LAU_NP,
a FORTRAN90 library which
contains heuristic algorithms for the
K-center and K-median problems.
SPAETH,
a FORTRAN90 library which
can cluster data according to various
principles.
SPAETH2,
a FORTRAN90 library which
can cluster data according to various
principles.
Source Code:
Examples and Tests:
Genetic expression data files include:
For data set 1039, there are the following files:
-
gene_cluster_1039_input.txt, an
input file describing the run to be made;
-
gene_cluster_1039.txt, the
output file containing the results;
-
normal_1039.txt, a table of the
energy versus number of clusters, for normalized data;
-
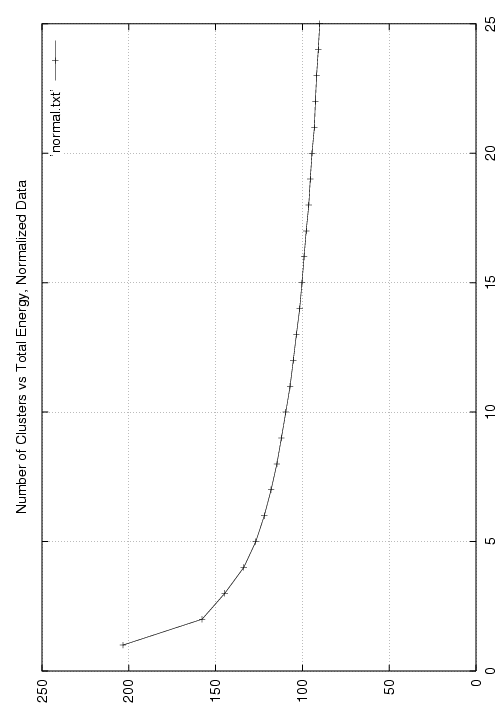
normal_1039.png,
a PNG image of
a plot of the
energy versus number of clusters, for normalized data;
-
normal2_1039.txt, a table of the
energy versus the inverse number of clusters, for normalized data;
-
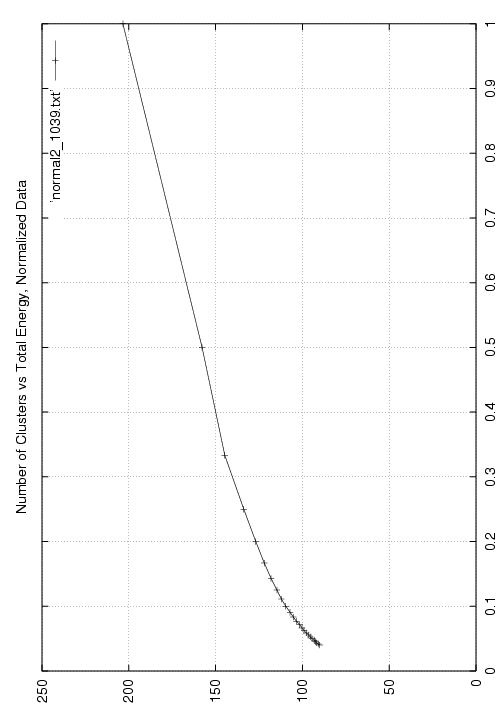
normal2_1039.png,
a PNG image of
a plot of the
energy versus the inverse number of clusters, for normalized data;
-
unnormal_1039.txt, a table of the
energy versus number of clusters, for unnormalized data;
-
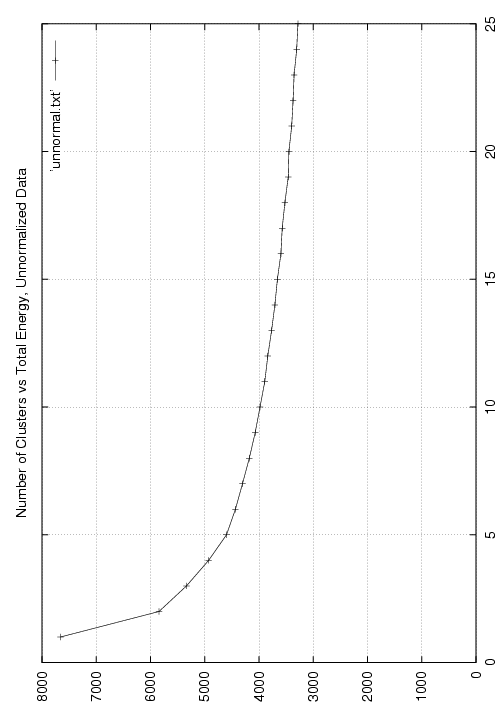
unnormal_1039.png,
a PNG image of
a plot of the
energy versus number of clusters, for unnormalized data;
-
unnormal2_1039.txt, a table of the
energy versus the inverse number of clusters, for unnormalized data;
For data set 1650, there are the following files:
-
gene_cluster_1650_input.txt, an
input file describing the run to be made;
-
gene_cluster_1650.txt, the
output file containing the results;
-
normal_1650.txt, a table of the
energy versus number of clusters, for normalized data;
-
normal2_1650.txt, a table of the
energy versus the inverse number of clusters, for normalized data;
-
unnormal_1650.txt, a table of the
energy versus number of clusters, for unnormalized data;
-
unnormal2_1650.txt, a table of the
energy versus the inverse number of clusters, for unnormalized data;
List of Routines:
-
MAIN is the main program for GENE_CLUSTER.
-
ANALYSIS computes the energy for a range of number of clusters.
-
CLUSTER_ITERATION seeks the minimal energy of a cluster of a given size.
-
DATA_TO_GNUPLOT writes data to a file suitable for processing by GNUPLOT.
-
ENERGY_COMPUTATION computes the total energy of a given clustering.
-
FILE_COLUMN_COUNT counts the number of columns in the first line of a file.
-
FILE_LINE_COUNT counts the number of lines in a file.
-
GET_UNIT returns a free FORTRAN unit number.
-
I4_INPUT prints a prompt string and reads an integer from the user.
-
I4_RANGE_INPUT reads a pair of integers from the user, representing a range.
-
I4_UNIFORM returns a scaled pseudorandom I4.
-
NEAREST_POINT finds the center point nearest a data point.
-
POINT_GENERATE generates data points for the problem.
-
POINT_PRINT prints out the values of the data points.
-
S_INPUT prints a prompt string and reads a string from the user.
-
S_REP_CH replaces all occurrences of one character by another.
-
S_TO_I4 reads an integer value from a string.
-
S_WORD_COUNT counts the number of "words" in a string.
-
TIMESTAMP prints the current YMDHMS date as a time stamp.
You can go up one level to
the FORTRAN90 source codes.
Last revised on 12 November 2006.
{kind=link}
{kind=link}
{kind=link}