HISTOGRAM_DATA_2D_SAMPLE is a C++ program which demonstrates how to construct a Probability Density Function (PDF) from a table of sample data over a 2D region, and then to use that PDF to create new samples.
The program presented here is hard-wired to handle a specific problem. However, the ideas used in the program are easily extended to other regions and other dimensions.
For the problem given here, we assume we have sample values of a function F(X,Y) for each subregion of a region. These values might actually represent population counts, a density, the integral of some function over the subregion, or simply an abstract function. We implicitly assumed that all the values are positive.
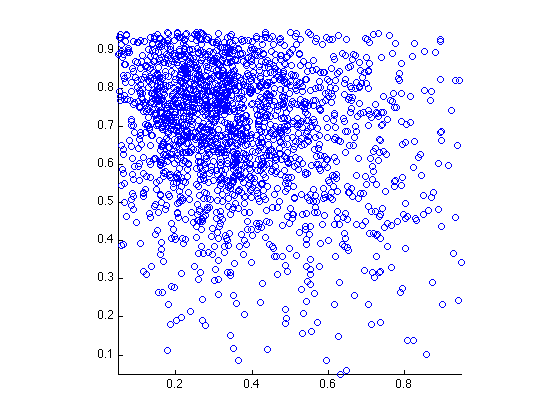
The particular region studied here is the unit square, which has been broken down into a 20x20 array of equal subsquares.
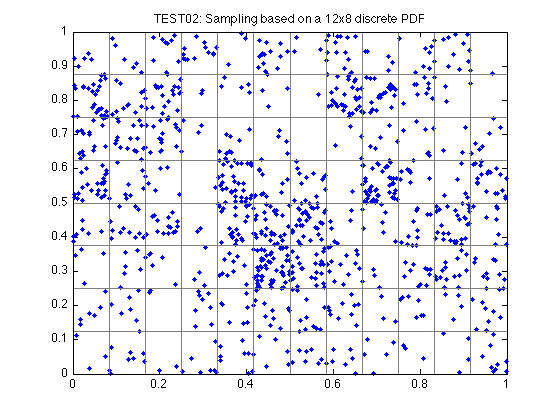
If we normalize by the sum of the data values, the result is a PDF associated with each subregion. By assigning an arbitrary order to the subregions, we can add the PDF values up to the given subregion to get a CDF (cumulative density function) for that subregion. Now given an arbitrary random value U, we can locate the subregion whose CDF value just exceeds U. Choosing a random point within this subregion gives us the sample point. If we choose many such sample points, the statistics for this sample will tend to the discrete PDF that we defined from the data we were given.
The computer code and data files described and made available on this web page are distributed under the GNU LGPL license.
HISTOGRAM_DATA_2D_SAMPLE is available in a C version and a C++ version and a FORTRAN90 version and a MATLAB version.
FEM1D_SAMPLE, a C++ program which samples a scalar or vector finite element function of one variable, defined by FEM files, returning interpolated values at the sample points.
FEM2D_SAMPLE, a C++ program which evaluates a finite element function defined on an order 3 or order 6 triangulation.
PROB, a C++ library which evaluates and inverts a number of probabilistic distributions.
RANDOM_DATA, a C++ library which generates sample points for various probability distributions, spatial dimensions, and geometries;
WALKER_SAMPLE, a C++ library which efficiently samples a discrete probability vector using Walker sampling.
TEST01 computes 1000 samples, based on a 20x20 PDF table that is heavily biased toward the northwest corner.
TEST02 computes 1000 samples, based on a 12x8 PDF table that is loosely based on the population of counties in Iowa.
You can go up one level to the C++ source codes.
{kind=link}
{kind=link}